
Mechanized Warfare – Thoughts on Machine Learning-Driven Fraud Prevention
I was catching up on the latest updates in the ever-changing world of fraud when I came across Adjust’s elaborate and insightful 4 parts blog post on the subject.
Part 3, “Is machine learning the answer to fraud?”, was the one that caught most of my attention, where they discuss the disadvantages of machine learning in the fraud prevention process, mainly it’s unreliable nature when it comes to rejections.
Their bottom line regarding machine learning is fairly simple and we tend to agree with it:
“We’re still in the early stages of its use. As such, letting it (machine learning) loose to attack the problem of fraud is irresponsible, and can lead to some unexpected consequences”
As with any new concept, there are bound to be some difficulties, errors, and false positives, especially in a field where fraudsters always come up with new and complex ways to disguise their mischievous explorations.
“We have already seen fraudsters spoofing virtually any request, including a client’s own measurement systems, with ‘perfect’ looking data. This makes it harder to identify spoofed users even after a longer period of tracking their behavior”
Fraud techniques have been constantly evolving – from device farms and fraud bots to something as complex as SDK spoofing, which presents this ‘perfect’ looking data. The struggle to detect fraud is constant as fraudsters become more sophisticated and their fraud becomes harder and harder to detect.
Allowing machine learning to adapt to ever-changing human-made fraud, one might argue, is irresponsible. Human involvement is crucial in a process that continuously gets more complicated.
Another approach to machine learning is using black-box models, which is in effect using machine learning without being able to discern the decision-making process – hiding the faults of an imperfect process.
“Once a provider loses the ability to (or doesn’t want to) explain why an attribution was rejected, then it becomes opinion. Opinions can be argued over or disagreed with. And, if we start down this path, we’ll end up in a situation where networks could try to portray every filter as just another ignorable opinion”
This ‘opinion’ is easily agreeable – full transparency is slowly but surely becoming a default requirement made by advertisers, and trying to ‘hide’ behind a machine’s undisclosed decision when it comes to rejection discussions doesn’t really cut it.
But even in a transparent process, without the use of black-box models, solutions based on machine learning are far from perfect:
“Imagine that you want to drink water from a river. The water is heavily polluted by different sources, and there are a few signs that might suggest something is wrong. So, you decide that you need to check if the water is safe first, and after think about the means to remove any potential contaminants. This would mean understanding not only what pollutants look like, but coming up with a way to filter all of them.
With some difficulty, you create a sophisticated machine. It teaches itself how to detect any potential signs of a problem, and will warn you about what kind of pollution it finds.
Your machine proves to be great at telling exactly what kind of pollution it spots, especially as it sees more cases over time. However, does that mean it’s covered every type of pollution? And, can it be relied upon to then stop the pollution, without also removing water that’s safe to drink?”
The solution Adjust is hinting at in this example is the need for a human eye, in the form of a data/fraud analyst constantly monitoring and fine-tuning the ‘machine’. We definitely agree, and want to elaborate and add that there’s definitely a need for more than one (two, if you think about it) human eye(s).
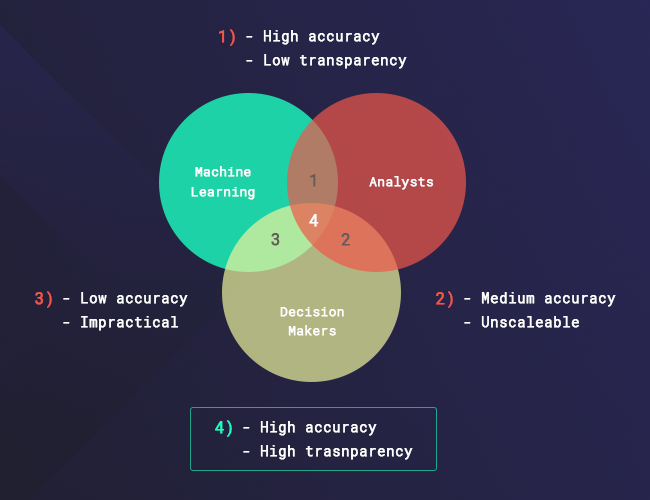
A senior decision-maker can shed light and notice data patterns that don’t make sense, because they live and breathe the industry and its changes – meeting and talking with colleagues, knowing the ins and outs of the industry, and having a much wider perspective compared to an analyst.
These people are the ones to go to when you need advice on which data you should be looking at. They go through the rejection process on a monthly basis and bridge the gap between publishers and advertisers on a daily basis and data scientists and analysts are the ones you need to help you ‘read’ the data, make sense of what the machine is learning, and ‘feed’ more data into it. Even with all three forces working together, there’s still room for error and no one can guarantee 100% fraud prevention.
Like Adjust, we agree that machine learning is unreliable for rejections at the moment. Having a person on the other side, tracking fraud, doesn’t guarantee complete success in prevention as well, but the combination of a team working with machine learning is the best plan we can come up with right now.











Thank you for your interest!
Our team will get in touch with you shortly.