Your source for everything mobile UA, from the basics to contentious standards, the glossary can help and inform both aspiring growth managers and experienced mobile app developers


Performance metrics
Creative Testing – Multi-Armed Bandit vs. A/B Testing -> Page 1 of
Creative Testing – Multi-Armed Bandit vs. A/B Testing
Creative testing is the way marketers compare the performance of different creatives in a campaign in order to evaluate which creatives yield better results. We will cover two methods: A/B testing, which is a commonly used method and widely known method, and the multi-armed bandit, which is less commonly known and used, usually due to its relative complexity.
These two methods offer very different approaches to creative testing, each with its own advantages and disadvantages. The aim here is to help marketers understand these differences and bring attention to some of the limitations of A/B testing and help them make a more informed decision.
A/B Testing
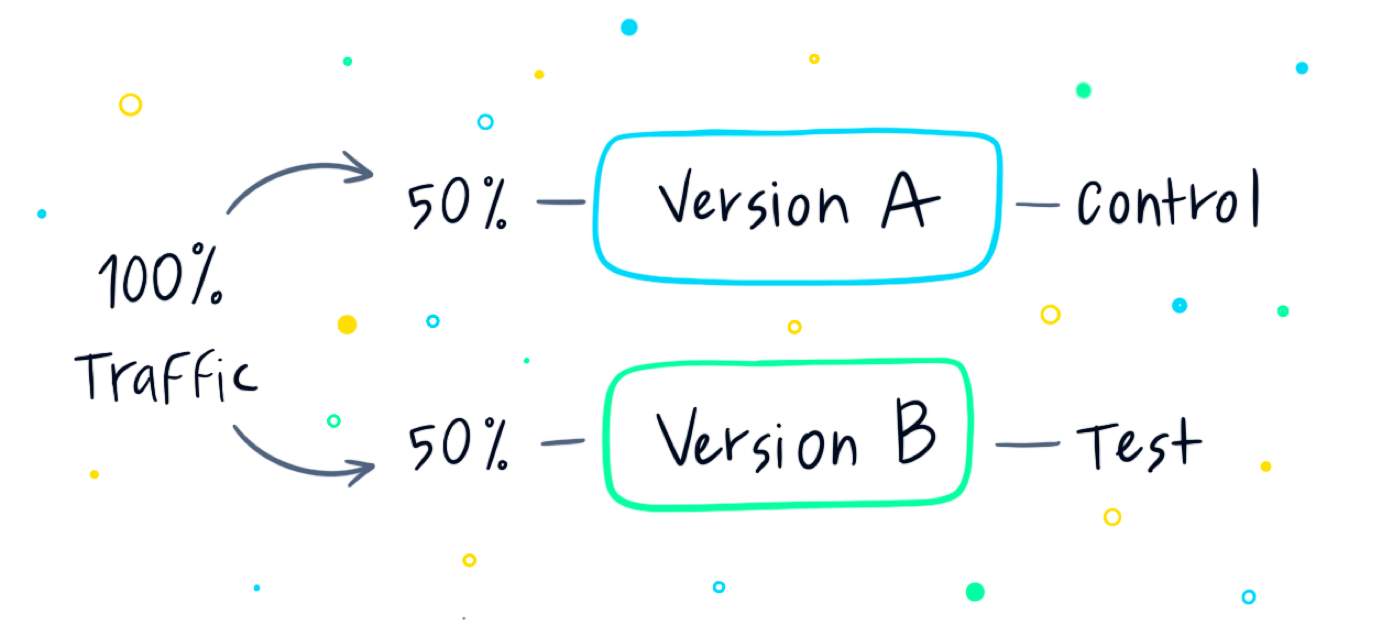
An A/B test (also known as an A/B/n test or a Split Test) is designed to try out different creatives in a win/lose scenario, resulting in a “Champion” (i.e, a single winning creative). These tests are executed by running different creatives for a set amount of users and a set amount of time. This initial stage of the campaign is referred to as the exploration stage. Then, the winning creative, i.e, the one yielding better results (be it clicks, conversions, or any other set goal) is the one chosen to run for the rest of the campaign. This second stage of the campaign is the exploit portion.

Thank you for your interest!
Our team will contact you with more details.
This type of test is rather simple to understand and set up. It’s useful for initial testing, and when there’s a need to choose a single champion. This may be useful to test out different creatives with starkly different styles, or when there are just a few creatives (2-3 options).

The Explore-Exploit Dilemma
Part of the reason that A/B testing is easy to understand and execute is that it offers a clear distinction between the exploration period and the exploitation period of the campaign. There’s a clear separation between the two stages.
The exploration period is the time in which all of the creatives are tested against one another on the same audience, and the exploitation period is when the winning creative runs exclusively. The name exploitation refers to taking advantage of the gathered data from the exploration period.
Other than its relative simplicity, A/B testing offers control during the exploration period since advertisers can set in advance the audience, as well as the running time, which means that they can limit the budget spent “unoptimized”.
The Caveats of A/B Testing
The simplicity of the test is inviting but there are some disadvantages that should be taken into consideration.
- Limited Testing – since the aim is to shorten the exploration as much as possible (as to not waste budget on less effective creatives), the audience on which the creatives are tested is significantly smaller than the overall audience. Marketers would want to choose the smallest possible audience to run these different ads on before settling on a creative, which means their sample might not be truly representative of the wider audience.
- Higher Overall Costs – even if marketers are testing their ads on the smallest possible audience, budget is still equally spent on creatives that aren’t working as well as the winning creative. They may be 1% worse than the winning creative, but they may also be 50% worse – and in both cases the spent on these creatives will be equal during the testing stage.
- May Be Arbitrary – there are no set best practices or simple correct settings for an A/B test. It depends on the size of the overall audience, the budget, the creatives, and how much they differ. The results may not be as conclusive as you’d like them to. You may get a very small margin separating between the winning creative and other tested creatives, which may be caused because the audience you’ve tested was too small or that both creatives were just as good, and there was no distinctive winner – a true “champion” creative.

While our focus here is on creatives testing, A/B testing can be used in many different ways. When explaining their split test tool, AppsFlyer mentions testing different media sources, ad placements, and more.
Adjust, on the other hand, offers running an in-app A/B test, as well as a marketing campaign test, and adds a few important best practices.
The Multi-Armed Bandit (MAB)
The name and concept of the multi-armed bandit are derived from slot machines. These machines are originally called one-armed bandits since their mechanics is that gamblers pull the lever, AKA the arm, and, in return, the machine ‘robs’ them.
The multi-armed bandit offers an alternative and more intricate way to test creatives. The MAB is a group of algorithms, based on the idea of the one-armed bandit. These algorithms offer different solutions for the theoretical problem a gambler faces in the casino – “what is the least expensive and fastest way to test all of the slot machines at the casino, assuming they vary in performance”.
The concept is “testing as you go”, as opposed to running an A/B test with a clear start and endpoint. In MAB, the test is ongoing, operating continuously throughout the campaign. In mobile marketing that would mean that the tested ads run in parallel, while the weight (i.e. percentage of the budget) given to each ad is decided by its performance.
Unlike A/B testing, in the different multi-armed bandit algorithms, the explore and exploit stages are intertwined.
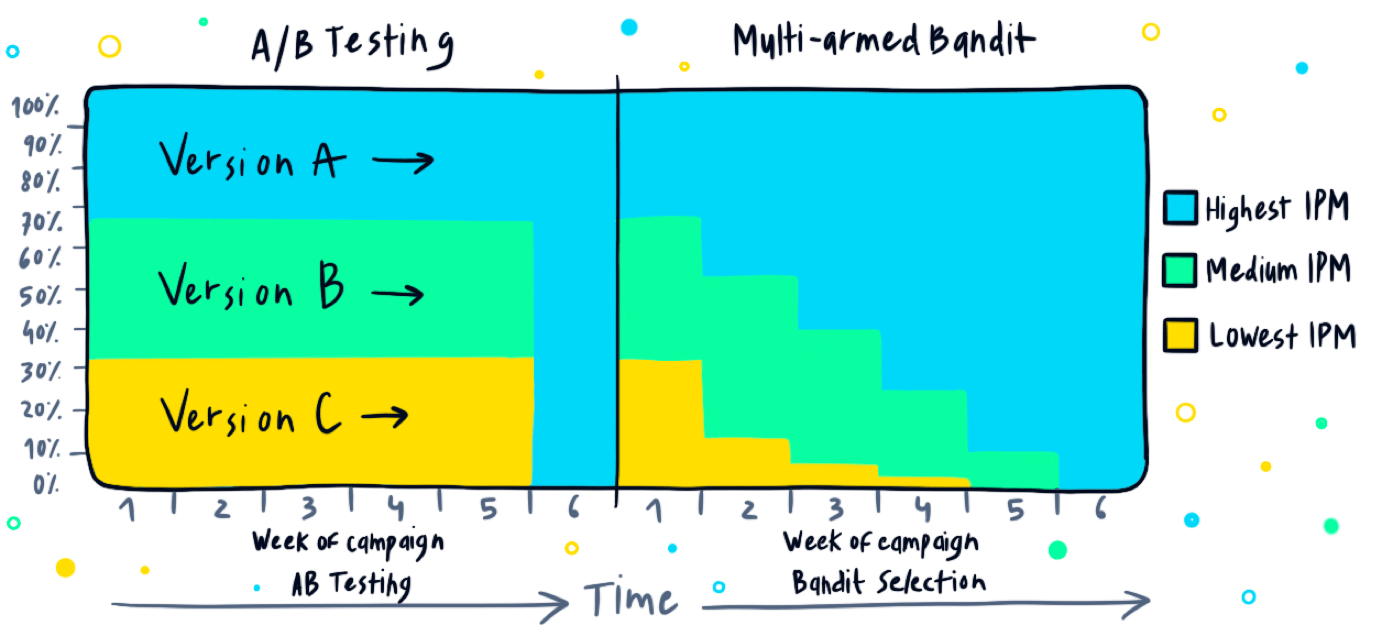
This solution uses an algorithm to constantly change the spending of each creative to coincide with its performance. This means that the best performing creative gets more budget, while the least performing one still runs, just with a smaller budget, and anything in between is still being used, based on its performance. There’s a range and the budget is relative.
Since there’s no distinction between the exploration period to the exploitation in MAB (the two stages happen simultaneously), MAB produces faster results and is widely proven to be more efficient than A/B testing.
Though the different MAB models differ, generally speaking, MAB models start to “move” traffic towards the winning variations as soon as they detect the slightest variation. This means that, unlike an A/B test, in MAB there’s no waiting for the end of the experiment, which means that MAB algorithms not only work faster, they also reach results at a lower cost, as long as the creatives actually perform differently from one another.

A/B Testing vs. MAB
- Trends in data – MAB results may change over time. One creative may become more popular than it was, initially. It may be impacted by varying factors, but it will be reflected in the data since the test runs continuously. A/B, on the other hand, only reflects the results of the limited time it ran in.
- Adding Creatives – since different creatives get different percentages of the budget, it’s easy to add new creatives to the mix and test them alongside the champion. If they “shine”, they gradually get more and more volume.
- Earning while learning – by combining the explore and exploit stages, MAB offers lower costs since the optimization starts while data is still being collected. The response is immediate and optimization kicks in faster..
- Automation – Bandits are a very effective way to automate creative selection optimization with machine learning, especially when considering different user features—since correct A/B tests are much more complicated in that situation. The MAB algorithm can be activated at very granular levels, and select the best creative for subsections of the targeted audience specifically, while other subsections would have different champions.
When Should You Use A/B Testing in Mobile Campaigns?
When comparing the two methods, it sounds like MAB is the way to go, and a way to save money and get quicker results. Nonetheless, there’s a reason for A/B testing’s popularity.
- If your app is new and you’ve yet to settle on a creative line and you want to test out a couple of very distinctive and different creatives, A/B testing is a way to get a conclusive yes\no answer (and if the margin is small, maybe you should run another test with different creatives).
- If your creatives are limited, and not endless. If you have 2-3 variations and not 10, it’s a simple way to decide between the versions without wasting your budget on multiple variations.
- The majority of acquisition channels don’t allow users to conduct MAB-based optimizations, only A/B testing. This option leaves marketers with a choice between A/B or no testing at all. In this scenario, A/B testing is better than nothing.
The Different Types of MAB Algorithms
Since it’s a complex topic, the aim here is to give a simplified version of the most relevant MAB models for marketing campaigns in general, and creative testing specifically.
Epsilon Greedy
Epsilon greedy, as the name indicates, is a MAB model that gives the largest part of the budget to the champion. In Epsilon Greedy, the person running the campaign decides on an epsilon (i.e, a percentage of the budget dedicated to the challengers) and the rest of the budget is allocated to the champion.
Let’s say the epsilon is set at 20%, this means that 80% of the budget of the campaign goes to running the champion, and the 20% is equally divided between the rest of the creatives. This means that epsilon greedy somewhat resembles an A/B test, but if there are changes in the performance during the campaign, a challenger may become the new champion.
Thompson Sampling
Thompson sampling, on the other hand, still utilizes the epsilon, but in its case, the challengers get budgeted in relation to their performance. Let’s say, again, that the epsilon is set at 20%. This means that 80% of the budget goes to the champion, while the 20% are divided based on their relative performance (some creatives will get 8% of the budget, some might get just 1%, and as the performance shifts, so will the budget).
The Upper Confidence Bound (UCB)
UCB may be referred to as the opposite of Thompson Sampling. UCB challenges the least explored creative to test if its low performance is related to the limited budget it’s been getting. When testing creatives, it’s least likely to be used, but when testing, for example, new inventory pockets with higher bids, it might yield interesting results.
If there are bid floors you’ve been avoiding, since they’re too high, it might be worth exploring, since these pockets of inventory might yield higher LTV users.
Contextual Bandits
Contextual bandits, as the name implies, are MAB algorithms that group around context. In the case of creative testing, contextual bandits may be grouped around gender, location, or other contextual relations and set a different champion and challengers for each group. This means that instead of a general competition between all of the creatives and the audience, the audience is segmented, and each segment gets its own champion.
Thank you for your interest!
Our team will contact you with more details.
