
Battling Publisher Fraud
Our latest fraud case study focused on our market research platform and uncovered how a single source systematically exercised fraudulent activity at scale. This follow-up article will focus on how we combat publisher fraud while running programmatic performance-based campaigns via OpenRTB.
The topic of fraud always occupies anyone involved in the mobile advertising world – as the ways to prevent it improve, new fraud tactics evolve and the cycle, unfortunately, continues. Moving into programmatic buying brought with it the hope that with all the data that’s available in a single ad request and all the possibilities that machine learning algorithms have to offer, fraud prevention will become easier, but as always, fraudulent activity evolves as its prevention tools improve.
Impression Level Fraud
Programmatic buying via OpenRTB allows for unparalleled levels of transparency for advertisers – it enables them to see exactly where the installs came from and track all the metrics at the placement bundle level (i.e. the apps where the ads were displayed).
When offering a performance-based model from day 1, as Persona.ly does, it’s inherently a low to a non-risk campaign, since most fraud in the programmatic world is the generation of fake impressions by malicious publishers (which get paid for impressions and have no incentive to fake installs… yet 😀 ) which means the advertisers not only get all of the information they need, they’re also guaranteed essentially fraud-free user acquisition campaigns.
While this is great news for the advertises, performance-based DSPs aren’t as fortunate, since they need to fend for themselves and ensure they don’t spend on manufactured impressions.
What Publisher Fraud Looks Like
In the past couple of years, anti-fraud providers have started distinguishing between two different types of fraudulent traffic-
- General Invalid Traffic (GIVT) – which can be relatively easy to detect by using lists and standardized checks. One example that can be rather easily identified is data-center traffic.
- Sophisticated Invalid Traffic (SIVT) – more complex methods that require machine learning and sometimes human intervention to detect. These are cases where publishers go out of their way to try and emulate real user behavior.
In reality, GIVT rarely slips under the radar, and detecting SIVT consistently, as it evolves is a different game entirely, mostly because the fraudsters have a say in the rules of said game.
How We Deal With the Mundane
- As a rule, we don‘t bid on incoming requests that don’t include an IDFA/GAID, ensuring we only bid on in-app traffic, and defacto eliminating a significant portion of GIVT fraud.
- Using a combination of device recognition data enrichment (like 51Degrees – click here to read a press release detailing some of the uses we have for their data) to build a device ‘risk score’ – allowing us to create a database of safe devices and focus our bidding on them.
- Using different IP validation tools like MaxMind to ensure the reported location in the requests checks out and that it’s not coming from data-centers.
That’s not all, but sharing the rest can make the mundane become unusual- and when it comes to battling fraud, we have our fair share of unusual and unexpected behavior.
How We Deal With the Uncanny
SIVT has many forms, and we have many different ways of detecting it. We won’t divulge all of them in a case study for obvious reasons, but we will share some specific cases our data science team picked up a while back.
Fraudsters are undoubtedly creative in their attempts to cover their tracks, but they still make mistakes. Earlier this year, following the decreased performance of one of the exchanges we are integrated with, our data science team started digging deeper into the requests from the said exchange during the 14-17 of February.
Our team then found that an abnormal amount of new devices started incoming from the exchange. Further investigation into these devices uncovered an alarming amount of suspiciously similar GAID strings.
As seen in the table below – we saw requests from dozens of different devices, with almost exactly the same sub-string (the fraudster bothered to only change 4 characters from the 32 character strings):
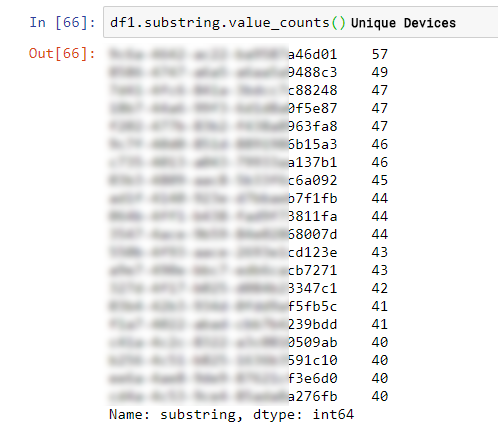
Two more alarming findings came from the additional analysis:
- All of the devices with the strings containing the repeating substrings completely disappeared from the system after the 17th – we didn’t see any additional requests from them.
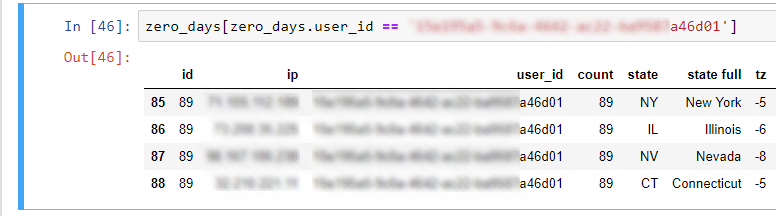
- When reviewing specific device id’s, we noticed some pretty… well, impossible user behavior. As seen below, we saw four requests from the same device, from four different states, in the span of 12 hours:
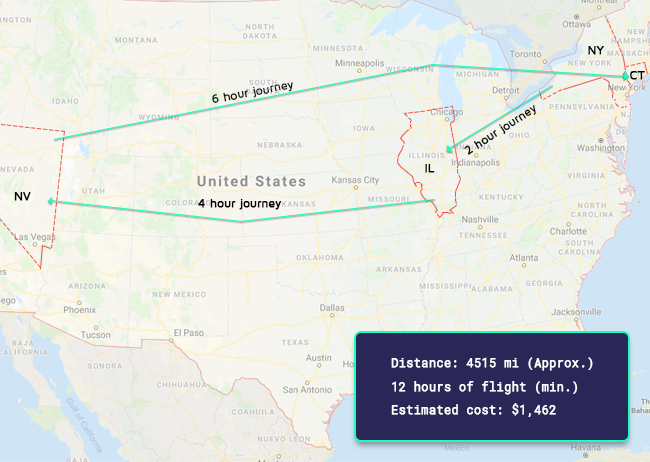
In reality, battling fraud is a significant, interesting, and challenging part of our daily routine. Besides helping our performance, it also helps us learn more about authentic user behavior, which is why we invest plenty of resources into developing machine learning-based detection tools as well as manual deep-dives by our data science and analytics teams.
Our team is exhibiting at MAU in Las Vegas next week – If you want to learn more about our fraud prevention abilities and our programmatic user acquisition services, drop by booth #313, or click here to set up a meeting with our team.












Thank you for your interest!
Our team will get in touch with you shortly.